코딩/Java
Collections framework3
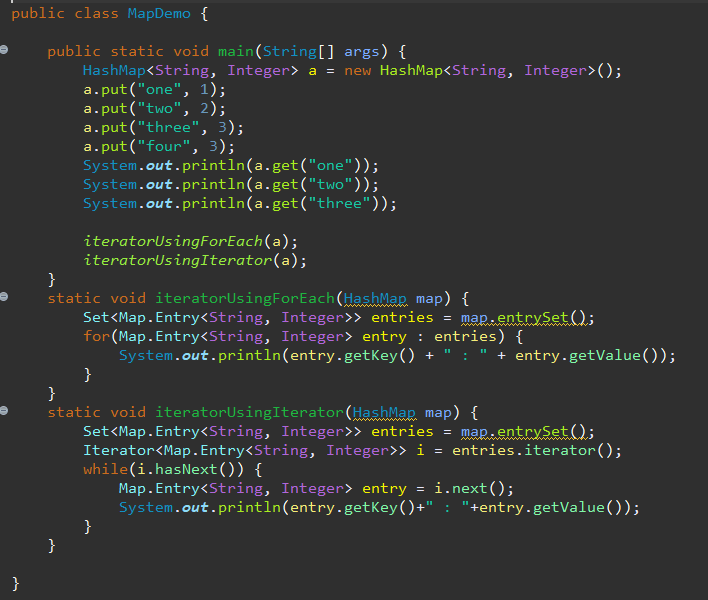
MAP : Map이라는 컨테이너에서 .entrySet()를 하면 셋 데이터 타입 컨테이너가 만들어진다. Map.Entry 데이터 타입은 getKey(), getValue를 가지고 있다. Collections의 사용 : 메소드 sort를 실행하면 내부적으로 compareTo를 실행하고 그 결과에 따라서 객체의 선후 관계를 판별하게 된다. 아직 잘 이해 안됨.
Collections framework2
컬렌션즈 프레임워크라는 것은 다른 말로는 컨테이너라고도 부른다. 즉 값을 담는 그릇이라는 의미이다. 그런데 그 값의 성격에 따라 컨테이너의 상격이 조금씩 달라진다. 자바에서는 다양한 상황에서 사용할 수 있는 다양한 컨테이너를 제공하는데 이것을 컬렉션즈 프레임워크라고 부른다. ArrayList는 그 중 하나이다. 전체적인 구성 : List와 Set의 차이점 : ArrayList는 값을 넣는 족족 중복에 상관없이 들어간다. 순서가 보장된다. 반대로 HashSet은 중복을 제외하고 값이 들어간다. 순서가 보장되지 않는다. 그래서 각자의 값이 고유하다. Iterator ai = al.iterator(); while(ai.hasNext()){ System.out.println(ai.next()); } 이번 코드는..
Collections framework
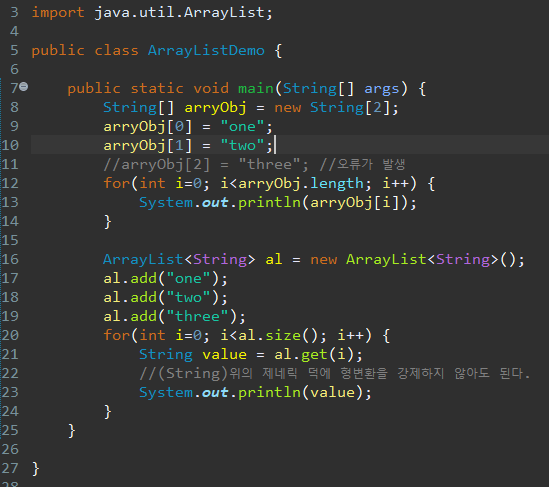
ArrayList : 이전 시간에 배열에 대해서 공부했다. 배열은 연관된 데이터를 관리하기 위한 수단이었다. 그런데 배열에는 몇가지 불편한 점이 있었는데 그 중의 하나가 한번 정해진 배열의 크기를 변경할 수 없다는 점이다. 이러한 불편함을 컬렉션즈 프래임워크를 사용하면 줄어든다. ArrayList는 크기를 미리 지정하지 않기에 얼마든지 많은 수의 값을 저장할 수 있다. ArrayList는 배열과는 사용방법이 조금 다르다 배열의 경우 값의 개수를 구할때 length를 썻지만 ArrayList는 size()를 사용한다. 또한 특정한 값을 가져올때 배열은 [인덱스 번호]지만 ArrayList는 .get(인덱스번호)를 사용한다.

제네릭
제네릭은 클래스 내부에서 사용할 데이터 타입을 외부에서 지정하는 기법을 의미한다. 위 코드의 p.infor와 p2.infor의 데이터 타입은 결과적으로 아래와 같다. p1.infor : String p2.infor : Stringbuilder 각각의 인스턴스를 생성할 때 사용한 사이에 어떤 데이터 타입을 사용했느냐에 달려있다. 제네릭의 사용 이유 : 위의 코드는 StudentPerson과 EmployyPerson가 사실상 같은 구조를 가지고 있다 중복이 발생하고 있는 것이다. 중복을 제거해보자. 클래스 Person의 생성자는 매개변수 info의 데이터 타입이 Object이다. 따라서 모든 객체가 될 수 있다. 그렇기 때문에 위와 EmployeeInfo의 객체가 아니라 String이 와도 컴파일 에..